


[Vol.7] 4차 산업혁명은 데이터 시대, XAI가 중요한 이유
4차 산업혁명은 데이터 시대, XAI가 중요한 이유
유성민 ([email protected])
동국대학교 국제정보보호대학원 외래교수
IT 칼럼니스트
(사이언스타임즈, 신동아, 더비체인 등 고정필진)
(사이언스타임즈, 신동아, 더비체인 등 고정필진)
4차 산업혁명은 세 가지 측면에서 3차 산업혁명에서 발전됐다. 초연결, 지능화, 신뢰성 등이 이에 해당한다. 초연결은 사물인터넷(IoT)으로 인한 연결의 확장을 의미한다. 3차 산업혁명은 사람 중심으로 인터넷 연결이 이뤄졌다면, 4차 산업혁명은 사물로 확장되고 있다. 시장 조사 전문 기관 ‘스태티스타(Statista)’는 2025년에 754.4억 개의 사물이 인터넷으로 연결될 것으로 전망했다.(1) 이는 전 세계 인구보다 10배가 넘는 수치이다.
더불어 지능화도 이뤄지고 있다. 2016년 3월 딥마인드(DeepMind)는 알파고를 선보이면서 인공지능(AI) 적용 영역이 더욱더 확장될 수 있음을 보여줬다. 실제로 AI는 자율주행, 번역, 이미지 인식 등 여러 분야에서 널리 활용되고 있다.
물론, 지능 수준도 3차 산업혁명과 비교했을 때 월등히 우수해졌다. 이미지 인식률에서 이를 확인할 수 있다. 이미지넷(ImageNet)은 2010년부터 매년 ‘대규모의 이미지 인식 경진 대회(ILSVR, ImageNet Large Scale Visual Recognition Challenge)’를 개최했었다.(2) 해당 대회는 가장 정확하게 이미지를 인식하는 시스템을 선발한다. 2013년 초기까지 대회 우승작을 살펴보면, 인식률이 90%를 넘기지 못했다. 그러나 2014년부터는 크게 개선되기 시작했다 (우승 시스템: GoogLeNet, 정확도: 93%). 그리고 2015년에는 마이크로소프트(MS)에서 개발한 이미지 인식 시스템이 우승했는데, 정확도가 96.43%로 사람의 이미지 인식률(94.9%)보다 더 뛰어났다. 그 후, ILSVR 대회는 2017년까지 계속 진행되었고, 정확도가 97.85%까지 향상되었다. 해당 수치는 2017년 기준이므로, 2019년에는 정확도가 더 향상됐을 것이다.
신뢰성 또한 4차 산업혁명의 특성으로 주목받고 있다. 블록체인 등장은 ‘신뢰성’이라는 새로운 가치를 사회에 제안하게 했다. (3)블록체인은 분산형 원장과 달리 합의 알고리즘이라는 기술이 뒷받침되는데, 이러한 기술은 블록체인이 데이터의 무결성을 보증케 한다. 참고로 블록체인은 제3자의 중개 없이도 더 강력한 무결성을 보증할 수 있는데, 이러한 이유로 블록체인은 탈중앙이라는 가치도 제공한다.
4차 산업혁명의 세 가지 특성 (3차 산업혁명과 비교)
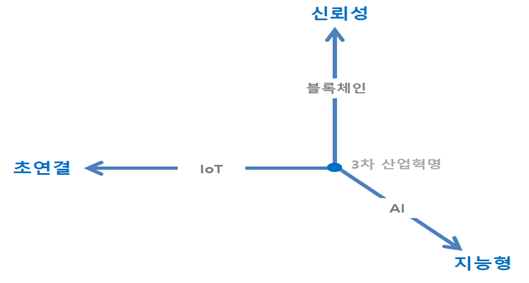
정리하면, 4차 산업혁명은 세 가지 유망 기술과 관련이 있다. 세 가지 기술이 새로운 변화를 이끌게 했기 때문이다. 그런데 세 가지 기술이 개별적으로 움직이는 것은 아니다. 다시 말해, 세 가지 기술은 무언가를 중심으로 동작하고 사회에 새로운 가치를 제공하고 있다. 이에 해당하는 중심이 무엇일까?
답은 ‘데이터’이다. 세 가지 유망 기술 모두 데이터를 중심으로 동작한다. 엄밀히 말해서, 그 외 클라우드, 엣지 컴퓨팅, 혼합현실(MR), 디지털 트윈 등 정보통신기술(ICT)의 거의 모든 유망 기술이 데이터를 중심으로 움직인다.
2016년에 4차 산업혁명 의미론 여부로 논란이 있었다. 당시, 일부 전문가는 4차 산업혁명과 3차 산업혁명의 구분 모호성을 제기하였다. 필자는 이에 ICBM(IoT, Cloud, BigData, Mobile) 모델을 들어서 3차 산업혁명과 4차 산업혁명을 처음으로 구분해서 설명한 적이 있다.(4) 참고로 ICBM 모델은 데이터 흐름을 단순히 표현한 것 뿐이다. IoT에서 데이터를 생성하면, 클라우드에 있는 빅데이터가 이를 분석하고 모바일로 의미 있는 정보를 전송 한다. 이것이 ICBM 모델이다.
그러면 여기서 필자가 언급한 세 가지 유망 기술은 데이터를 중심으로 어떻게 동작하는 것일까? ICBM과 크게 다르지 않다. IoT는 여전히 센서로서 데이터를 생성하는 역할을 맡는다. 그리고 AI가 이를 분석해 가치 있는 정보를 제공한다. 블록체인은 생성된 데이터와 분석된 정보의 무결성을 보증하는 역할을 맡는다.
4차 산업혁명의 세 가지 특성 (3차 산업혁명과 비교)

사실, 데이터는 3차 산업혁명 때부터 기술의 중심으로 작용해왔다. 3차 산업혁명은 정보 혁명으로 일컬어지며 이는 인터넷의 등장이 정보 공유를 세계적으로 촉진하였음을 의미한다. 가령, 도서관에 갈 필요 없이 인터넷 접속만으로 세계의 정보를 한눈에 확인할 수 있다.
물론, 3차 산업혁명 시대와 4차 산업혁명 시대에 데이터를 보는 눈은 다르다. 다시 말해, 데이터를 보는 관점 변화가 3차 산업혁명과 4차 산업혁명을 구분하는 잣대로도 활용할 수 있다.
4차 산업혁명과 빅데이터
3차 산업혁명과 4차 산업혁명을 데이터 관점에서 어떻게 구분할 수 있을까? 이는 생각보다 쉽다. ‘빅데이터’라는 기술 용어 하나만 가지고도 구분할 수 있기 때문이다. 빅데이터에는 4차 산업혁명이 가진 특성을 모두 포함하고 있다.
빅데이터 용어 등장은 2005년으로 거슬러 올라간다. 2005년 오라일리 미디어의 로저 더글라스(Roger Douglas)는 빅데이터라는 용어를 처음으로 언급했다.(5) 그러나 빅데이터 개념은 2012년 가트너가 정립할 때까지 모호한 상태였다. 가트너는 2012년 6월에 “빅데이터의 중요성: 정의”라는 보고서를 통해서 빅데이터를 처음으로 정의했었고(6), ICT 산업은 이때부터 빅데이터를 주목하기 시작했다.
가트너는 빅데이터를 규모(Volume)·속도(Velocity)·다양성(Variety)을 포함한 3V라는 용어로 정의했다. 규모는 데이터의 거대 용량을 뜻하는 용어이고, 속도는 대규모의 데이터를 빠른 속도로 처리할 수 있음을 의미하는 용어이다. 다양성은 정형적인 데이터뿐만 아니라 비정형적인 데이터도 분석 가능함을 의미하는 용어이다.
가트너의 정의에서 한 가지 알 수 있는 사실이 있다. 빅데이터는 데이터 자체를 뜻하기보다는 기존 데이터 분석 방식과 다른 새로운 분석 방식을 뜻하는 용어로 사용됐다는 점이다. 즉, 3차 산업혁명의 데이터 분석 방식과 구별되는 특성이 있다.
그럼 4차 산업혁명과 연관하여 빅데이터를 살펴보자. 먼저, 규모는 IoT와 연관이 될 수 있는데 IoT는 700억 개가 넘는 사물에서 무수히 많은 데이터를 생산하기 때문이다. 그리고 다양성은 AI와 연관이 있다. 기계학습(ML) 기반 AI는 비정형 데이터까지 분석하여 의미 있는 정보를 추출할 수 있다.
빅데이터에 추가로 필요한 특성 ‘정확성’
최근 빅데이터는 7V로까지 확장되어서 설명되고 있다. 그러나 7V는 단순히 홍보 용어로서 과장된 것으로 보이기도 하는데, 살펴보면 의미 없는 특성이 붙여진 경우가 많기 때문이다. 가령, 가치(Value), 시각화(Visualization) 등이 새롭게 추가되고 있다. 두 가지 특성은 사용자에게 의미 있는 정보를 제공해 정확한 판단을 이끄는 의미로 사용된다. 그러나 시각화는 가치에 포함될 수 있으므로 무의미한 특성이다. 이는 가치 또한 마찬가지이다. 빅데이터는 데이터 분석 의미로 해석되며, 데이터 분석은 당연히 의미 있는 정보를 추출을 목표로 한다. 그러므로 가치라는 특성도 3V에 붙이는 것은 바람직하지 않게 보인다.
필자의 생각으로는 정확성(Veracity)이라는 특성이 추가되어 4V 정도까지 확장하는 것이 바람직해 보인다. 하지만 빅데이터에서 정확성을 구현하기는 쉽지 않다. 정확성은 두 가지 의미를 내포하고 있다. 첫째는 분석되는 데이터의 정확성이고 둘째는 데이터 분석 방법의 정확성이다. 첫 번째 부분은 블록체인이 어느 정도 해결해주는데 IoT에서 생산한 데이터를 블록체인이 보증할 수 있기 때문이다. 물론, IoT 자체의 오류로 잘못된 기록은 블록체인이 보증할 수 없는 한계가 있다. 참고로 이를 오라클 문제라고 한다.
문제는 두 번째 부분으로 3차 산업혁명 시대에는 별로 크지 않은 문제로 여겨졌다. 그러나 4차 산업혁명 시대에는 가장 중요하게 다뤄야 할 부분으로 인식되고 있다. AI 구현이 ML 중심으로 이뤄지고 있기 때문이다.
AI는 시스템에 사람과 같은 지능을 구현하는 기술이다. 지능은 사람이 가진 사고로 정의할 수 있는데, 이는 사람의 가치관과 행동을 결정하는 역할을 한다. 그럼 이러한 지능은 어떻게 구현되는 것일까? ‘학습’에 의해서 구현된다. 물론, 이는 AI에서도 마찬가지이다.
AI 또한 학습이 중요하다. 사실 AI는 사람이 만든 공식에 의해서 동작하였다. 다시 말해, 동작 공식을 AI에 심는 방식이었다. 그러므로 AI 동작 원리는 투명했고, 개발자가 이를 충분히 관리할 수 있었다. 그런데 이러한 동작 원리는 ML 등장과 함께 변하고 있다. AI가 데이터를 보고 직접 학습하여 공식을 만들어내는 원리이다. ML은 AI가 복잡한 원리를 이해하고 동작하는 데에 유용하다. 다만, 단점은 AI 동작 원리가 블랙박스처럼 투명하지 않다는 것이다. AI가 스스로 학습 규칙을 만들기 때문이다.
정리하면, 빅데이터는 4V 원칙이 중요하기 때문에 정확성이 추가될 필요가 있다는 뜻이다. 이는 ML 등장으로 인한 AI 동작의 불투명성과 관련이 있으며 4가지 문제를 일으킨다.
첫째는 AI 동작 신뢰도 문제이다. 의료 분야에 AI를 적용한다고 가정했을 때, 의사는 환자를 진단하고 결과에 대한 원인을 설명해준다. 이는 환자에게 신뢰감을 주기 위해서이다. 그런데 AI 기반 의료 시스템은 이를 설명해줄 수 없다. AI의 진단 방식이 불투명하게 가려져 있기 때문이다.
둘째는 AI 개발 관리 어려움이 있다. AI도 편향성을 가지기 때문에 동작 방식이 정확하지 않을 수 있다. 이와 같은 상황에서는 AI 보정이 필요하다. (7)그러나 이는 쉽지 않은데 AI가 잘못된 공식을 가지고 올바르게 판단하는 것처럼 행동하는 경우가 많기 때문이다. 실제로, 어느 연구팀은 ML 기반 AI로 늑대를 판별하는 시스템을 만들 었다. 그런데 AI는 눈(Snow)이 배경인 늑대 사진을 기반으로 학습하였고, 이에 늑대를 판별할 때 사진 속에 눈이 있는지를 확인하였다. 따라서 해당 AI는 허스키 사진이 등장할 때마다 잘못된 판단을 내리기도 했다. 허스키 사진에도 배경이 눈인 경우가 많았기 때문이다.
셋째는 책임 소재이다. AI가 이상하게 동작하는 경우, 과연 누가 책임을 져야 할까? AI 개발자에 책임을 묻기는 어려운 것이 개발자는 AI 동작 원리의 통제력을 보유하고 있지 않다. 그러므로 상황에 따라 AI 개발 기관의 도덕적 해이를 불러올 수 있다. 모든 책임을 AI에 떠넘기면서 회피할 수 있기 때문이다. 경제협력개발기구(OECD)의 경우에는 AI와 담합 문제를 언급하면서, AI 기반 거래 시스템으로 인해 발생한 담합 문제 책임 소재를 밝히기 어렵다고 지적한 바 있다.(8) AI 동작 원리가 블랙박스처럼 가려져 있기 때문이다.
마지막 문제는 불안감이다. AI가 사람을 공격할 수 있다는 불안감으로, 공상과학영화에서 여러 차례 언급되어 온 주제이다. 이러한 불안감은 AI의 통제 불능과 관련이 있으며, 실제로, 수많은 석학은 AI 시대를 우려하고 있다. 특히, AI를 활용한 전쟁 무기 ‘킬러 로봇’의 경우에는 많은 석학이 인류를 위협하는 물건을 만들어내는 것으로 경고하고 있다.(9)
AI 생각을 말해주는 XAI
앞서 언급하였듯이 4차 산업혁명 시대는 빅데이터 시대로도 볼 수 있다. 3V가 주목받고 있던 셈이다. 그러나 3V로는 부족하며 정확성이 추가로 필요하다. ML 기반 AI 시대에는 특히나 중요하다. AI의 동작 원리를 설명하는 기술이 필요하다. 이러한 기술은 다행히 이미 개발되고 있으며 ‘설명 가능 인공지능(XAI, eXplainable Artificial Intelligence)’이라고 부른다.
엔비디아(NVIDIA)는 그래픽 프로세스 제공 전문 기업에서 AI 전문 기업으로 탈바꿈하고 있는데, 자율주행 시스템 기술 개발에 이어서 자율주행 원리를 보여주는 기술도 2017년에 선보였다. 엔비디아는 ‘파일럿넷(PilotNet)’ 이라는 기술을 개발했는데, 해당 기술은 자율주행시스템이 주위 사물을 어떻게 인지하고 운전하는지를 설명 해준다. 그 외 미국 국방부 산하 연구기관 방위고등연구계획국(DAPRA)은 AI 시대 위험에 대비하기 위해서 XAI 연구에 착수했다.(10)
국내에서도 XAI 연구가 진행되고 있다. 울산과학기술원(UNIST)은 한국과학기술원(KAIST), 고려대, 연세대, 서울대 등과 협력해 ‘설명가능 인공지능 연구센터’를 개소했다. 아울러, UNIST는 과학기술정보통신부로부터 4년 6개월간 최대 154억 원을 지원받아서 XAI 개발을 진행하고 있다. 의료(세브란스 병원)와 금융(코스콤)을 실증 대상으로 XAI 기술을 실증할 예정으로 네이버, 포스코 등에 본 과제에서 개발한 기술을 공급할 계획이다.
이처럼, XAI 개발 착수가 진행됐다. 그럼 XAI는 어떤 원리로 구현할 수 있을까?
방법은 단순해 보이지만 어렵다. AI 판단 결과를 역추적해서 보는 수밖에 없다. 이와 관련한 알고리즘 기술이 이미 개발되었으며 가장 단순한 알고리즘으로 ‘민감도 분석(Sensitivity Analysis)’이 있다. 민감도 분석은 투입 값을 변화시키면서 결과값을 확인하고 투입 요인의 비중을 산출하는 알고리즘 기술이다.
개별조건예측(ICE, Individual Conditional Expectation)(11)과 부분의존구성(PDP, Partial Dependence Plots)(12)의 방법으로도 AI 구현 방법을 추론할 수 있다. ICE는 민감도 분석과 유사하다. 투입값 대비 결과값 변동을 보고 투입 요인 비중을 판별한다. PDP는 이러한 ICE의 표준값이다. PDP는 여러 독립 요인을 묶어서 민감도 분석과 유사하게 요인을 분석한다. 다시 말해, ICE는 개별 요인 비중을 분석한다면, PDP는 묶음 단위로 비중을 분석한다.
.
또 다른 방법 모델로 ‘일부 해석 모델 – 불가지로 설명(LIME, Local Interpretable Model – Agonistic Explanations)’이 있다. LIME은 다수 요인을 투입값을 넣었을 때의 결과값을 보고 AI 동작 원리를 분석하는 알고리즘 기술이다. 첨가 요인 민감도(SHAP, SHarply Additive exPlanations)는 특정 요인을 제외함으로써 해당 요인의 민감도를 계산하는 알고리즘이다. 다시 말해, 특정 요인의 첨가 전후를 비교해서 민감도를 계산하는 것이다.
지금까지 설명한 방식은 AI가 내놓은 결과값을 보고 역 추적하는 방식이다. 이를 설명한 이유는 XAI로 이러한 알고리즘 기술이 주로 쓰이고 있기 때문이다. 더불어 XAI 방식은 앞으로 더 다양해질 전망이다. DAPRA는 이러한 방법 외에도 두 가지 방안을 제안했다. 첫 번째 방법은 AI 추론에 활용된 요인에 라벨을 붙여 이를 시각화해 보여주는 것이다. 두 번째는 AI 생각을 감시하는 또 다른 AI를 만드는 것이다. 또 다른 AI의 역할은 AI 동작 원리를 끊임없이 추론해 알려주는 것이다.
AI 기술이 확산하고 있어 앞으로 AI를 통제할 수단이 필요한 상황이다. 이에 XAI가 주목받기 시작했다. 또한, 다양한 방식으로 AI 동작 원리를 추적하는 기술이 등장할 전망이다.
본 원고는 KISA Report에서 발췌된 것으로 한국인터넷진흥원 홈페이지(https://www.kisa.or.kr/public/library/report_List.jsp)에서도 확인하실 수 있습니다.
KISA Report에 실린 내용은 필자의 개인적 견해이므로, 한국인터넷진흥원의 공식 견해와 다를 수 있습니다.
KISA Report의 내용은 무단 전재를 금하며, 가공 또는 인용할 경우 반드시 [한국인터넷진흥원,KISA Report]라고 출처를 밝혀주시기 바랍니다.
| 1. | ⇡ | Statista Research Department, “Internet of Things (IoT) connected devices installed base worldwide from 2015 to 2025 (in billions)”, November 2016. |
| 2. | ⇡ | 사이언스타임즈, “불안전한 AI 통제, 어떻게 해결할까?”, 2018년 09월. |
| 3. | ⇡ | 유성민, “미래 사회에 지능을 더하다: 블록체인과 혁신 서비스”, 한국정보화진흥원(NIA), 2019년 02월, 1-95쪽. |
| 4. | ⇡ | 유성민, “ICBM 현황과 스마트시티 구축방안”, 2016년 지역정보화 이슈 리포트(6호), 한국지역정보개발원(KLID), 2016년 06월, 1-22쪽. |
| 5. | ⇡ | 사이언스타임즈, “빅데이터로 경제 가치를 갖게 된 데이터”, 2019년 07월. |
| 6. | ⇡ | Mark Beyer and Douglas Laney, “The Importance of ‘Big Data’: A Definition”, June 2012. |
| 7. | ⇡ | Ribeiro, M.T., Singh, S., and Guestrin, C., “Why Should I Trust You”, Explaining the Predictions of Any Classifier, CHI 2016 Workshop on Human Centered Machine Learning, February 2016. |
| 8. | ⇡ | OECD, “Algorithms and collusion”, June 2017. |
| 9. | ⇡ | 신동아, “예측 불가능 학습, 오작동·해킹도 위험”, 2017년 02월. |
| 10. | ⇡ | David Gunning, “Explainable Artificial Intelligence(XAI)”, DAPRA/I2O, April 2019. |
| 11. | ⇡ | Goldstein, Alex, et al. “Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation.” Journal of Computational and Graphical Statistics, vol. 24, 2015, pp. 44-65 |
| 12. | ⇡ | Friedman, Jerome H. “Greedy function approximation: A gradient boosting machine.” Annals of statistics, 2001, pp. 1189-1232. |
![[Vol.12] 개인정보 정책에서 증거기반(evidence-based)의 규제의 필요성](https://hiic.re.kr/wp-content/uploads/bfi_thumb/dummy-transparent-qzswzze6g081azganrruhb07lbpw5dlcswvfm3xzys.png)