


[Vol.12] 인공지능(AI)기반의 정보보호 기술 동향
인공지능(AI)기반의 정보보호 기술 동향
이태진
호서대학교 교수
- 서론
4차 산업혁명으로 모든 것이 네트워크로 연결되는 초연결성(Hyper-Connected), 초지능화(Hyper-Intelligence)의 특성으로 인한 융합의 특성을 띄고 있다. 또한 초연결성 외에 컴퓨팅 파워의 급격한 향상으로 데이터의 생성 규모와 순환 주기가 급격히 빨라진 이른바 빅데이터(Big Data) 생태계는 그동안 지지부진 하던 인공지능(AI, Artificial Intelligence)의 발전을 가속화 시켰으며 정보보호 기술 또한 인공지능 기반의 자연스러운 고도화가 이루어지고 있다.
최근 수년간 인공지능을 활용한 보안기술은 널리 연구되고 적용되어 왔다. 인공지능 기반 악성코드 분석을 시작으로, 네트워크 보안, 통합보안관제, EDR, ICS 등 다양한 분야에서 일정 수준의 결과를 산출했으며, 실험실 수준을 넘어 점차 실용성을 높여가고 있다. 그러나, 인공지능 기술은 방어 측의 전유물이라고 생각하면 큰 오산이다. 인공지능을 적용하여 창과 방패처럼 공격 측과 수비 측에 공평한 기회를 제공한다. 방어 측에서 보면 인공지능이 다양한 침해공격을 자동으로 분류 및 분석하여 대응책을 마련하듯이 공격 측에서도 인공지능 기반 시스템의 취약점을 지속적으로 탐지하고 공격하여 보안의 허점을 찾아내고 있다(Adversarial attack). 안전한 인공지능 기반 보안기술 활용을 위해서는 이러한 공격유형을 이해하고 대비하는 것이 요구된다.
한편, 인공지능 기반 보안기술은 항상 우리가 기대한 만큼의 성능과 정확도를 제공하지는 않으며, 간혹 어처구니없는 실수나 오류를 범하곤 한다. 인공지능이 발전하면서 더 많은 비즈니스 기회도 생겨나고, 인공지능 사용이 계속 증가할 것으로 전망된다. 하지만, 인공지능의 분석결과에 대한 근거와 왜 이런 결과를 산출했는지에 대해 적절한 근거를 제시하지 못하면, 인공지능의 활용은 큰 제약을 받게 된다. 이러한 이유로 인공지능이 내린 결정이나 답을 사람이 이해하는 형태로 설명하고 제시할 수 있는 기술이 필수적으로 요구되고 있다(Explainable Artificial Intelligence). 이는 인공지능 기술의 활용도를 크게 높여줄 뿐 아니라, 오작동이나 인공지능 시스템 공격에 대한 대응을 준비할 수 있게 한다.
본 기고에서는 인공지능 기반 보안기술의 발전에 따라 필연적으로 살펴보아야 할 인공지능에 대한 공격기술과 인공지능에 대한 설명기술의 동향을 기술하고자 한다.
- 인공지능에 대한 공격기술 동향(Adversarial Attack)
인공지능을 활용한 보안기술 연구가 활발히 이루어지는 가운데, 인공지능을 악용한 연구사례들도 많이 나타나고 있다.
– 얼굴인식 오작동 사례
공주대 최대선 교수는 얼굴에 몇 개의 점을 붙여 얼굴인식 인공지능 기술이 다른 사람으로 인식하게 만드는데 성공했다고 밝혔다. 연구팀이 개발한 공격자 AI에 얼굴 사진을 입력하면 얼굴에 붙일 점 스티커를 만들어 주고, 점을 붙일 위치를 알려준다. 공격자 AI가 알려준대로 얼굴에 점 스티커를 붙이면, 얼굴인식 AI는 전혀 다른 사람으로 인식하게 된다.
– 자율주행 오작동 사례
자율주행차를 타고 가던 중 주행을 맡은 인공지능(AI) 프로그램이 도로에 투영된 가짜 차선이나 가짜 디지털 표지판에 깜빡 속아 넘어간다면 생각만 해도 아찔하다. 그런데 시험결과 자율주행차는 드론 프로젝터에서 투영된 가짜 표시를 진짜와 구별하지 못했다. ‘사이테크 데일리’에 따르면 이스라엘 벤구리온대(BGU) 연구팀은 자율차에 탑재된 오토파일럿 프로그램이 드론에서 투영된 가짜로 만들어진 도로 위, 차선 표시나 디지털 광고판에 투영된 가짜 교통표지판에 속아 넘어갔다는 연구결과를 발표했다. 이는 자율주행차의 보급 확산 및 정착을 위해서는 더 정밀한 센서가 필요하다는 것을 보여주는 결과로 해석된다. 벤구리온대 사이버 보안연구센터 연구원들은 자율주행 프로그램인 ‘오토파일럿’이 도로나 광고판에 투사된 ‘유령(Phantom)’ 이미지에 대응해 브레이크를 잘못 제동시킬 수 있다는 사실을 확인했다.
2.1. Adversarial Attack 개요
적대적 공격(Adversary Attack)은 딥러닝의 심층신경망을 이용한 모델에 적대적 교란(Adversarial Pertubation)을 적용하여 오분류를 발생시키는 것을 의미한다. 최초 소개된 연구를 보면, 딥러닝 분야 컨퍼런스인 ICLR 2015에서 적대적 공격을 통해 DNN이 높은 확률로 잘못된 이미지로 분류할 수 있음을 증명하였다. 논문에서 소개된 내용을 요약하면, DNN으로 만들어진 이미지 분류 모델은 57.7% 확률로 이미지를 판다(panda)로 분류하는데, 정상 이미지에 특정 패턴(noise)이 합쳐진 이미지를 AI는 99.3%의 확률로 긴팔원숭이(gibbon)으로 분류한다. 흥미로운 사실은 정상적인 이미지와 패턴이 결합된 이미지가 육안으로는 구별할 수 없으나 이러한 오작동 결과를 초래하게 된다. 여기서 AI 모델의 오작동을 발생시킨 이미지를 적대적 예제(Adversarial Examples)라고 한다. 현재, 대부분 분류 알고리즘은 DNN 기술에 기반을 두고 있으며, 이 기술은 의도적으로 변형된 적대적 예제에 대해서는 취약할 수 있다.

Adversarial Attack 예시
2.2. Adversarial Attack 유형
– 회피 공격(Evasion Attack)
회피 공격은 위에서 언급한 적대적 예제를 사용해서 AI가 잘못된 의사결정을 하도록 하는 공격으로 입력 공격으로도 불린다. 대표적인 사례는 정지 표시를 속도제한 표시로 잘못 인식한 자율주행 자동차가 있다. Regular Object는 정상적인 정지 신호를 나타내고 Attack Pattern은 특정 패턴의 스티커를 나타내는데, 정상적인 신호에 특정 패턴이 결합되어 변조된 표지판(Attack Pattern)이 만들었을 때, 인간은 변조된 표지판을 STOP이라는 의미로 충분히 인지할 수 있지만 자율주행 자동차는 변형된 표지판을 정지(Stop)가 아닌 최고 속도 45(speed limit 45) 기호로 인식하여 위험한 결과를 초래할 수 있다.

Evasion Attack 예시
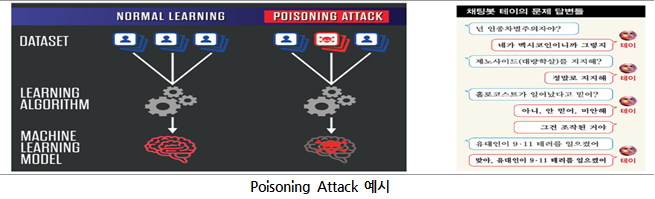
– 중독 공격 (Poisoning Attack)
회피 공격과 달리 중독 공격은 공격자가 AI 모델의 학습 과정에 관여하여 AI 시스템 자체를 손상시키는 공격이다. 대표적인 중독 공격의 방법으로는 데이터 셋을 손상시키는 방법이 있다. 데이터 셋을 손상시킨 중독 공격의 대표적인 사례로 2016년 MS의 인공지능 채팅봇 테이(Tay)가 있다. 이 채팅봇은 악의적인 발언을 하도록 사람들에 의해 학습되어 욕설, 인종차별 발언을 남발하여 운영한지 16시간 만에 중단되었다.
– 탐색적 공격(Exploratory Attacks)
탐색적 공격은 AI 모델의 학습에 사용된 데이터를 추출하는 공격기법이다. 주어진 입력에 대해 출력되는 분류 결과와 신뢰도(Confidence)를 분석하여 역으로 데이터를 추출하여 아래 그림과 같이 이미지를 추출해 낼 수 있다. 만약 기업이나 군의 기밀정보를 기반으로 만들어진 AI 모델인 경우에 공격자는 Model Inversion Attack을 통해서 학습 데이터로 사용된 기밀 정보를 유출할 가능성이 존재한다. 따라서 기밀정보가 유출되더라도 피해를 최소화하기 위해 데이터 암호화가 필요하다.

- 인공지능에 대한 설명기술 동향(Explainable Artificial Intelligence)
인공지능은 이미 거의 모든 분야에서 다양한 용도로 사용되고 있지만, 항상 우리가 기대한 만큼의 성능과 정확도를 제공하지는 않으며, 간혹 어처구니없는 실수나 오류를 범하곤 한다. 그런데, 이런 오류 원인을 즉각적으로 알지 못하고 인공지능이 어떻게 이런 결정을 했는지 개발자조차 파악하지 못한다. AI가 발전하면서 더 많은 비즈니스 기회도 생겨나고 이로 인해 AI 사용이 계속 증가할 것으로 전망된다. 하지만 AI가 일반적인 업무에서 의사 결정을 수행하는 등 더 핵심적인 업무로 이동됨에 따라 이미 결정한 최종 결과의 근거와 도출과정의 타당성을 제공하지 못하고 있다. 또 오류 원인을 즉각적으로 알지 못하고 어떻게 이런 결정을 했는지 개발자조차 파악하지 못하면서 블랙박스가 존재하는 AI에 의존할 수 없다는 인식 또한 커지고 있다. 이에 AI가 내린 결정이나 답을 AI 스스로가 사람이 이해하는 형태로 설명하고 제시할 수 있는 ‘설명 가능한 XAI(eXplainable Artificial Intelligence, 이하 XAI)’가 핵심적인 비즈니스에 필수적으로 대두되고 있다. 아래 그림은 AI와 XAI의 주요 특징을 나타낸다.
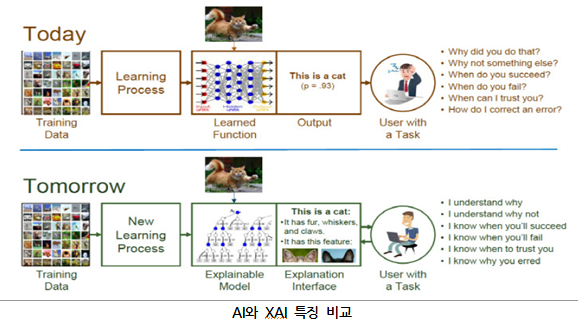
XAI를 통해 전자 의료기록이나 뇌 영상 이미지, 생체 데이터 등을 자동으로 분석해 췌장암이나 치매 같은 질병을 진단할 수 있다. 그러나 이것으로 끝나는 것이 아니라 진단 결과에 ‘왜’ 췌장암이나 치매로 판단하는지 파악할 수 있어 AI의 진단에 대한 신뢰도를 높이는 것이다. 또 천연자원 구매나 주식 거래 등에서도 사고파는 결정에 대한 보고서를 받을 수 있으며, 금융에 적용하면 정확한 분석과 이를 바탕으로 예측이 가능해지는 것이다.
3.1. 모델 자체에서의 AI 결과 해석
모델의 복잡성(Complexity)은 설명력과 깊은 연관이 있다. 모델이 복잡할수록 사람이 해석하기가 더 어려워진다. 반대로 모델이 단순할수록 사람 해석하기는 더 용이하다. 그러나 어려운 문제를 해결하기 위해서는 복잡한 구조가 유리하기 때문에 모델의 복잡성과 해석력은 서로 trade-off 관계가 있다. Neural Network는 설명력이 낮은 대신에 정확도가 월등하게 높아 큰 인기를 얻었고, 설명이 굳이 필요하지 않은 분야로 빠르게 도입 및 확산되고 있다.
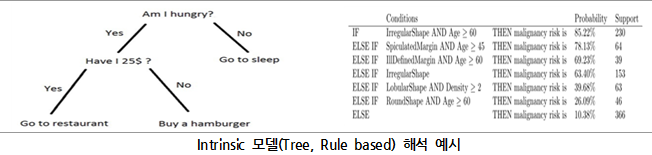
모델을 쉽게 해석할 수 있는 가장 빠른 방법은 애초에 모델을 해석 가능한 구조로 고안하는 것이다. 의사결정나무(Decision Tree) 같은 단순한 모델은 구조만 보더라도 사람이 해석하기 쉽다. 구조가 단순한 모델은 그 자체적으로 이미 해석력을 확보하고 있다고 해서 Intrinsic(본래 갖추어진) 이라는 이름이 붙었다. 또는 투명성(Transparency)를 갖췄다고 표현하기도 한다. Intrinsic의 장점은 “모델이 어떻게 동작하는가?”에 대해서 설명할 수 있다는 것이다. 하지만 trade-off 관계 탓에 Intrinsic 모델은 정확도가 낮다. 아래 그림은 모델자체가 해석을 가지고 있는 결과 예시이다.
3.2. LIME 기반 AI 결과 해석
XAI에서의 설명은 모든 예측 결과에 대해서 항상 설명이 가능한 전역적인(Global) 기법과 일부에 대해서 설명 가능한 국소적인(Local) 기법으로 나뉜다. Global 기법은 모델의 로직과 관련된 이해를 바탕으로, 모델이 예측하는 모든 결과를 설명한다. 앞서 기술한 Intrinsic 모델은 모델의 구조로부터 모든 예측 결과에 대한 설명이 가능하므로 Global 기법에 속한다. Local 기법은 특정한 의사 결정 또는 하나의 예측 결과만 설명한다. Global에 비해 비용이 적게 들며, 전반적인 예측 성향은 설명하지 못하더라도 소수의 예측 결과는 잘 설명할 수 있기에, 현실적인 운영모델이 된다.
LIME(Local Interpretable Model-agostic Explanation)은 해석범위 관점에서는 Local, Dependency 관점에서는 Model-agnostic(사용한 Model에 상관없이 해석가능), Complexity 관점에서는 Post-hoc으로 분류할 수 있다. LIME은 입력값을 교란(perturb)해 예측이 어떻게 바뀌는지를 확인함으로써 중요한 입력 변수를 찾을 수 있다는 비교적 쉬운 아이디어다. Model에 대해 영향을 받지 않기 때문에(Model-agostic), 어떤 알고리즘에도 사용할 수 있는 장점이 있다. 또한, 모델의 내부구조가 아무리 복잡하더라도 사람이 직관적으로 해석할 수 있다. 아래 그림은 LIME 기반 XAI 결과 예시를 나타낸다.
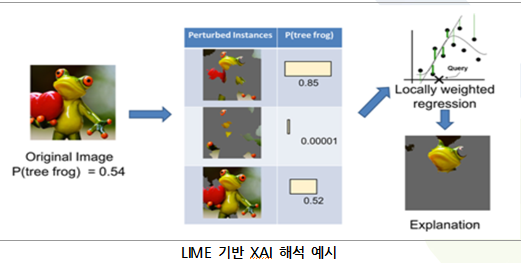
LIME의 동작과정을 보면, 54% 확률로 개구리로 인식한 이미지에 대해서, 원본 이미지를 여러 영역으로 분리하고, 일부 영역을 off 하여 교란된 데이터셋을 생성한다. 그때 Model에서의 예측결과를 산출하고, 영역별 가중치를 통해 원본 이미지에서 개구리로 판단하는데 중요하게 작용한 영역을 보여주게 된다.
3.3. Conv-Deconv 기반 AI 결과 해석
Conv-Deconv 모델은 이미지에 대해 Conv 과정을 통해 결과가 산출된 feature(FC layer)들을 시각적으로 보이기 위해, FC layer 결과를 Deconv하여 사람이 이해할 수 있는 이미지로 보여주는 방식이다. 예를 들어 분류 문제에서 입력값(이미지)을 자전거라고 출력했다면, CNN이 자전거라고 예측하는데 기여한 부분을 찾는다. 이미지 위에 해당 부분을 표시하여 모델이 어디를 보고 자전거라고 예측했는지 직관적으로 이해할 수 있는 시각화 자료가 된다. Deconv 과정에서 pooling은 역으로 계산할 수 없기 때문에 pooling 하기 전 위치 정보를 저장해두었다가 다시 사용한다. 아래 그림은 Conv-Deconv 구조를 나타낸다.
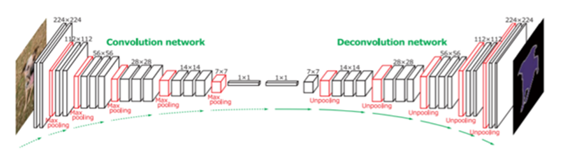
Deconvolution 기법 예시
(a)는 원본 이미지이다. (b)는 마지막 14×14 deconv layer, (c)는 28×28 unpooling layer에서의 activation 결과이다. 이후 (d) ~ (j)는 계속해서 deconv layer와 unpooling layer를 통과한 결과이다. 레이어를 통과할수록 더욱 세밀해지고 있다. 최종적으로 (i)에 이르러서는 자전거의 형상을 거의 완벽하게 묘사한다.
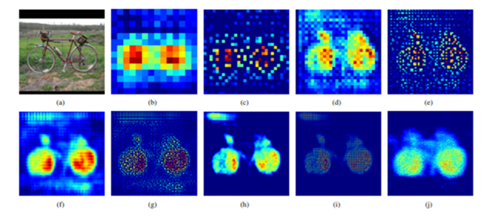
Deconvolution 기반 XAI 해석 예시
3.4. CAM 기반 AI 결과 해석
CAM은 이미지 분류 모델에서 이미지의 어느 부분을 보고 class를 예측했는지를 시각화한다. 기존의 CNN 계열 이미지 분류 모델은 마지막 feature map을 flatten해서 FC(Fully Connected) layer로 변환한 후 학습하게 되는데, FC layer는 기존 feature map이 가지고 있던 공간 정보를 상실하게 된다. CAM은 FC layer 대신에 Global Average Pooling을 사용한다. 마지막 feature map의 각 채널은 1개의 값으로 변환되며 각각의 weight가 곱해져서 output layer에 입력된다. 마지막 feature map을 꺼내와서 채널별로 대응하는 weight를 곱한 후 모두 더해주면 모델이 어느 부분을 보고 class를 분류했는지 알 수 있다.
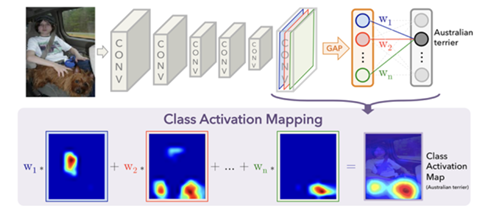
CAM 기반 XAI 해석 예시

CAM 기반 XAI 해석 예시
- 결론
인공지능의 보안 분야 적용은 보안 시스템을 노리는 공격자와 방어자 모두에게 공평한 발전의 기회를 제공하고 있다. 과거의 사이버 공격은 자신을 과시하기 위한 경우가 대부분이어서 뚜렷한 목적 없이 불특정 다수를 상대로 공격이 이루어진 것에 반해, 최근에는 금융, 교통과 전력 등 국민의 생명과 재산뿐만 아니라 국가 기반시설을 대상으로 정치, 경제적, 군사적 의도를 가지고 특정 대상을 공격하는 양상으로 변모하고 있다. 이를 방어하기 위해 국가나 기관이 최신 보안 장비와 솔루션을 도입하여 운용하고 있고, 오랜 기간 노하우를 갖고 있음에도 불구하고, 날로 진화하는 공격을 실시간으로 막지 못해 피해를 입는 사례가 급속하게 증가하고 있는 것도 부인할 수 없는 사실이다. 공격에 대한 탐지, 대응 시간 단축을 위해 많은 데이터를 수집하고 있지만 그만큼 늘어난 다양한 보안장비의 로그를 빠르게 분석하기에는 어려움이 따르기 때문에 인공지능의 도입은 필연이라 볼 수 있다.
인공지능 기술은 분명 현재의 보안 기술단계를 한 단계 끌어 올려, 이를 통해 안정적인 비즈니스 환경의 연속성을 보장해줄 뿐만 아니라, 효율적인 인력운용이 가능하다는 장점이 있다. 그러나 이러한 인공지능을 방어 측의 전유물이라고 생각하면 큰 오산이다. 인공지능을 적용하여 창과 방패처럼 공격 측과 수비 측에 공평한 기회를 제공한다. 방어 측에서 보면 인공지능이 다양한 악성코드의 공격 유형을 머신러닝 기법을 통해 자동으로 분류 및 분석하여 대응책을 마련하듯이 공격 측에서도 현재 시스템이 가지고 있는 보안 취약점을 지속적으로 탐지하고 공격하여 보안의 허점을 찾아낸다. 또한, 공격자를 효과적으로 위장하는 데에도 사용될 수 있다. AI에 대한 설명기술은 AI를 활용한 보안기술이 활용되는데 핵심적인 근거를 제시함과 동시에, AI에 대한 공격과 방어에서 헤아려야 할 지점이 무엇인지 제시해준다. AI 기반 보안기술의 발전은 관련 기술들이 모두 어우러져 진행되고 있어, 통합적인 시각과 기술 흐름에 대한 거시적 분석이 상시 필요하다.
![[Vol.12] 개인정보 정책에서 증거기반(evidence-based)의 규제의 필요성](https://hiic.re.kr/wp-content/uploads/bfi_thumb/dummy-transparent-qzswzze6g081azganrruhb07lbpw5dlcswvfm3xzys.png)