


[Vol.7] 컴퓨터 비전 분야에서 AI 보안에 대한 연구 동향
컴퓨터 비전 분야에서 AI 보안에 대한 연구 동향
김호원 ([email protected])
부산대학교 교수
인공지능(Artificial Intelligence, AI) 기술에 대한 연구는 2번의 침체기를 지나고 현재 전성기를 누리고 있다. 2012년 “ImageNet Large Scale Visual Recognition Challenge (ILSVRC)”라는 이미지 인식 대회에서 Convolution Neural Network(CNN) 구조의 딥러닝(deep learning) 알고리즘이 우승한 뒤로 2015년에는 사람의 능력을 뛰어넘는 성능의 딥러닝 알고리즘이 등장하였다. 딥러닝 알고리즘은 연구자들의 많은 관심을 받으며 개선되고 이미지 인식과 같은 컴퓨터 비전 분야 뿐만 아니라 자연어 처리, 음성 처리 등 다양한 분야로 확장되어 연구되었다. 2016년에는 알파고와 프로 바둑 기사의 대국 이후로 대중의 관심도 받게 되어 AI 기술에 대한 연구는 더욱 활발히 연구되고 있다.
AI 기술은 자율 주행 자동차, 얼굴 인식, 번역, 로봇 제어 등 다양한 산업에 활용되며 연구 및 개발되고 있다. 하지만 AI 기술이 산업에 활용되면서 취약점에 대한 우려가 나오고 있다. 가트너에서는 매년 주요 기술 트렌드를 조사하여 정보를 제공하는데, AI 보안에 대한 기술을 2020년 주요 기술 전략 탑 10으로 선정하였다.(1) AI 보안에 대해 회피 공격(evasion attack), 오염 공격(poisoning attack), 모델 추출(model extraction), 모델 전도(model inversion) 등 다양한 연구가 존재한다. 그 중 컴퓨터 비전 분야에서 중요하게 연구되는 적대적 예제(adversarial examples)에 대한 연구 동향을 다루어본다.

적대적 예제
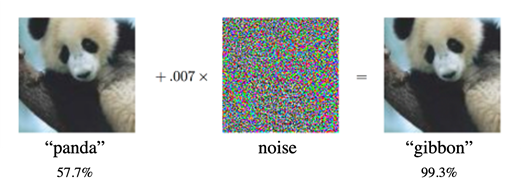
적대적 예제는 AI 모델에 이미지를 입력하여 오동작하게 만들기 위해 신중하게 조작한 이미지를 말한다. 대표적인 예시로 판다(panda) 이미지에 미세한 노이즈(noise)를 추가하여 AI 이미지 분류 모델이 긴팔원숭이(gibbon)로 오분류 하도록 만들 수 있다[1].
초기 연구에서는 사람의 눈에 띄지 않기 위해 노름(norm)과 같은 제약조건으로 이미지 변화를 제한하였다. 이후 원본 이미지와 비교해서 눈에 띄는 변화가 있더라도 위화감이 없이 자연스럽게 동일한 의미 정보를 가지는 적대적 예제를 생성하기 위한 연구가 제안되었고, 디지털 환경에서 이미지를 조작하는 연구에서 확장하여 실제 피지컬 환경에서 패치를 부착하는 등 카메라에 캡처되는 이미지를 조작하여 AI 모델을 공격하는 연구가 수행되고 있다. 또한 컴퓨터 비전 분야에서 AI 모델의 발전과 더불어 이미지 분류 모델, 객체 탐지 모델, 객체 추적 모델 등으로 적대적 예제에 대한 연구도 범위를 넓히고 있다.
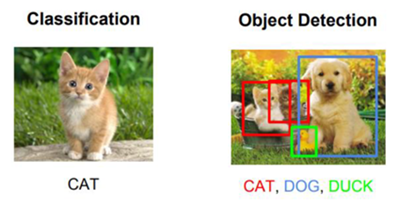
객체 탐지 모델에 대한 적대적 예제
컴퓨터 비전 분야에서 AI 기술을 적용하기 시작한 초기에는 ILSVRC 대회를 개최하는 등 이미지 분류 문제를 해결하였다. 이후 더 복잡한 객체 탐지 문제를 해결하기 위해 고안된 모델들이 제안되었다. 이미지 분류 문제는 이미지에 해당하는 클래스가 무엇인지 맞춘다면 객체 탐지 문제에서는 이미지가 입력으로 주어졌을 때 이미지에 포함되는 객체의 클래스와 위치까지 예측한다. 예를 들어 고양이 사진이 주어졌을 때 고양이라고 예측하는 것이 분류 문제라면 이미지 내의 고양이의 위치까지 특정 하는 것이 객체 탐지 문제에서 해결하고자 하는 과제이다. 해결하고자 하는 문제가 다르기 때문에 분류 모델, 객체 탐지 모델 각각에 대해서 적대적 예제를 생성하는 접근 방법도 달라지게 된다. 분류 모델에 대한 적대적 예제의 결과로 고양이를 개로 오분류하게 만든다면 객체 탐지 모델에서는 고양이를 개로 오분류하게 만들거나 고양이가 없다고 인식하게 만들 수 있다. 분류 모델과 비교해서 객체 탐지 모델에서는 하나 이상의 존재하는 객체의 유무/위치/클래스를 예측해야 하는 복잡한 문제이다. 또한 실제 활용되기 위해서는 움직이는 카메라의 위치, 조명, 배경 등 물리적인 환경 요소를 고려해야 한다.
물리적 환경을 고려한 적대적 예제
디지털 환경과 달리 현실 세계의 피지컬 환경에서는 적대적 예제와 이미지 픽셀이 동일하게 공격 대상이 되는 AI 모델에 입력하는 것은 어려운 일이다. 이미지의 픽셀을 조작하더라도 인쇄로 인한 변조, 카메라 각도/거리에 의한 변조, 카메라 노이즈에 의한 변조, 주변 조명에 의한 변조 등 다양한 변수에 의해 최종적으로 AI 모델에 입력되는 이미지는 공격자가 원하는 적대적 예제가 아닐 것이다. 그래서 이러한 물리적 제약사항에도 효과적으로 AI 모델을 오동작시키는 견고한(robust) 적대적 예제 생성 방법들이 제안되고 있다. Expectation over Transformation(EoT) 라는 기법을 통해 이미지 스케일링, 회전, 밝기 변화 등에 적대적 예제를 견고하게 만들고 Total Variation(TV)을 통해 카메라 노이즈 등 잡음 문제를 처리한다. 또한 Non-Printability Score(NPS) 라는 점수를 계산하여 인쇄하였을 때의 차이가 거의 없도록 만드는 연구가 수행되었다. EoT 기법을 제안한 연구에서는 거북이 모형을 3D 프린터기로 출력하여 카메라로 캡처하였을 때 라이플로 오인식하는 실험 결과를 제시하였고 NPS를 도입한 연구에서는 안경을 인쇄하여 얼굴 인식을 방해하는 실험을 통해 현실에서 적대적 예제가 효과적으로 공격됨을 보였다[2,3].


물리적 제약사항을 극복하기 위한 적대적 예제 실험을 현실에서 하는 것은 많은 시간과 인적 자원 등을 필요로 한다. 이를 해결하기 위해 시뮬레이션 환경에서의 실험 결과를 제시하는 연구들이 생겨났다. 시뮬레이션 환경에서 쉽게 배경, 조명, 카메라 위치 등을 제어하고 AI 모델이 오인식 하도록 객체에 정밀하게 생성한 패치를 붙이거나 객체의 텍스처를 수정하여 특정 패턴을 만든다. 시뮬레이션 환경으로 언리얼엔진 4, CARLA, AirSim 시뮬레이터 등이 사용된다.

하지만 아직까지는 시뮬레이션 환경에서 생성된 적대적 예제가 현실에서 효과적으로 적용되기엔 무리가 있다. 현실과 시뮬레이터 사이의 간극(sim2real gap)이 크기 때문이다. 이 차이를 줄이기 위해 도메인 랜덤화(domain randomization) 기법을 적용할 수 있다. 도메인 랜덤화는 시뮬레이션 환경에서 객체가 가지고 있는 속성을 임의로 변경하여 합성 데이터(synthetic data)를 생성하는 기법이다. Meta-sim이라고 제안된 연구에서는 현실 데이터와 합성 데이터가 가지고 있는 고차원의 의미 정보 차이를 줄이기 위해 장면 그래프(scene graph)와 장면 그래프의 속성을 변경하는 오토인코더(auto-encoder) 구조의 모델을 통해 현실과 유사한 이미지를 생성하였다[5].

(왼쪽: 합성 데이터, 오른쪽: 실제데이터)
또 다른 시뮬레이션 환경에서의 적대적 예제에 대한 연구 한계점으로 렌더링 방법이 있다. 시뮬레이터에서 3D 객체를 배경과 함께 2D 이미지로 렌더링하여 화면에 보이기 위해서 다양한 알고리즘이 사용된다. 현존하는 많은 시뮬레이터에서는 미분 불가능한 렌더링 도구를 사용하는데, 이럴 경우 화이트박스(white-box) 공격에 어려움이 발생한다. 화이트박스 상황에서 공격자는 공격 대상이 되는 모델의 구조, 파라미터 등 AI 모델이 배포된 환경의 모든 정보를 가지고 있다고 가정한다. 화이트박스를 가정하는 경우 이미지를 입력하여 AI 모델의 출력으로부터 기울기(gradient)를 계산하고 역전파(back-propagation)하여 입력되는 이미지를 수정하는 적대적 예제가 일반적이다. 하지만 시뮬레이션 환경에서 AI 모델에 입력하기 위한 이미지의 픽셀을 직접적으로 수정하는 것이 의미 없기 때문에 2D 이미지를 렌더링하기 위해 필요한 객체의 모양, 텍스처, 색상 등의 정보를 수정해야 한다. 만약 렌더링 알고리즘이 미분 불가능하다면 AI 모델 출력으로부터 기울기를 역전파 할 수 없기 때문에 객체 정보를 수정하는데 문제가 생긴다. 이를 해결하기 위해 미분 가능한 렌더링 연구가 수행되고 있다.
블랙박스 환경을 고려한 적대적 예제
산업에서 사용되는 AI 모델은 전체 시스템에서 하나의 구성 요소이다. 그렇기 때문에 타겟 시스템에 대한 접근 권한을 획득하거나 또 다른 방법으로 AI 모델에 대한 정보를 얻는 것은 굉장히 제한적일 것이다. 즉, 화이트박스 상황을 가정하는 것은 매우 강력한 가정이다. 그래서 블랙박스(black-box) 상황에서의 공격 연구가 진행되고 있다. 공격 대상이 되는 타겟 모델에 쿼리를 보내 그에 대한 출력을 얻고 입력, 출력 여러 쌍에 대한 정보를 통해 타겟 모델을 모사한 모델에 화이트박스 공격을 하는 방법이 제안되었다[6]. 이후 모델 내부의 기울기를 추정하여 적대적 예제를 생성하는 Zeroth Order Optimization(ZOO) 공격과 진화 알고리즘(genetic algorithm)을 활용한 GenAttack이 제안되었다[7,8]. 또한 시뮬레이션 환경에서 렌더링 과정에서 미분 불가능한 문제를 블랙박스 환경이라 보고 이를 해결하려는 연구가 수행되었다. CAMOU에서는 객체, 배경, 텍스처 정보를 입력받아 타겟 모델의 출력을 모사하는 모델을 통해 적대적 예제를 생성하였다[4].
또 다른 블랙박스 문제를 해결하기 위한 접근법으로 공격 전이성(transferability)에 대한 실험 결과를 제시하고 있다. 공격 전이성이라는 것은 전이 학습(transfer learning)에서 말하는 “유사한 문제를 해결하는 AI 모델은 공통되는 정보를 가지고 있을 것”이라는 것을 적대적 예제에 적용한 것이다. 예를 들어 A라는 모델에 대해서 화이트박스로 적대적 예제를 생성하였다면 그 적대적 예제는 B라는 모델에서도 오동작을 일으킨다는 것이다. 사용된 적대적 예제는 A 모델에는 화이트박스지만 B 모델에게는 블랙박스이기 때문에 정보를 모르는 어떠한 모델에서 공격 가능성을 보이기 위해 공격 전이성 실험 결과를 제시한다.
적대적 예제에 대한 보안
앞부분에서는 적대적 예제의 위험성, AI 모델의 취약성에 대한 내용을 소개하였고 이를 방어하기 위해서 다양한 연구 결과가 제시되고 있다. 연구 초기에 제안되고 아직까지 유효하다고 여겨지고 있는 방법으로는 적대적 학습(adversarial training)이 있다[1]. 적대적 학습은 적대적 예제를 생성하여 그것을 재학습하는 방법으로 모델의 견고함(robustness)을 개선할 수 있다. 적대적 학습은 AI 모델이 학습하는 데이터를 더욱 다양하게 만드는 효과를 보이기 때문에 데이터 증강(augmentation) 기법으로 활용되는 경우도 있다. 적대적 예제를 방어하는 또 다른 접근 방법으로는 인증된 방어(certified defence) 기법이 연구되고 있다[9]. 인증된 방어는 일정 범위내의 이미지 변조에 대해서 안전함을 보장한다. 하지만 적대적 학습과 인증된 방어 방법 모두 적대적 예제 공격 가능성은 여전히 존재한다.
AI 모델이 사용되는 코드를 테스트하기 위해 Cleverhans(2), Adversarial Robustness Toolbox(ART) (3)같은 라이브러리가 존재한다. ART는 적대적 예제 외에도 오염 공격, 모델 추출 공격 등 모델의 방어 능력을 평가해 볼 수 있고 다양한 프레임워크(Tensorflow, PyTorch 등)에서 다양한 데이터 셋(이미지, 오디오 등)으로 다양한 작업(이미지 분류, 객체 탐지, 음성 인식 등)을 테스트할 수 있다.
AI 모델의 취약성을 막는 연구만으로 완벽한 보안을 이루는 것은 어려운 일이다. Adversarial Threat Landscape for Artificial-intelligence Systems(ATLAS) (4) 매트릭스에는 기존 보안 전문가들과 AI 모델의 위협을 공유하기 위해 MITRE ATT&CK 프레임워크와 유사한 형태로 AI 모델의 보안 위협 내용이 정리되어 있다. ATLAS에는 AI 모델의 취약점과 관련된 보안 접근법뿐만 아니라 AI 모델을 공격하기 위해 관련 정보를 획득하는 방법, 모델을 포함하는 시스템에 접근하는 방법, 공격 시나리오 등 시스템, API 등에 대한 보안 가이드라인을 제시하고 있다.

본 원고는 KISA Report에서 발췌된 것으로 한국인터넷진흥원 홈페이지(https://www.kisa.or.kr/public/library/IS_List.jsp)에서도 확인하실 수 있습니다.
KISA Report에 실린 내용은 필자의 개인적 견해이므로, 한국인터넷진흥원의 공식 견해와 다를 수 있습니다.
KISA Report의 내용은 무단 전재를 금하며, 가공 또는 인용할 경우 반드시 [한국인터넷진흥원, KISA Report]라고 출처를 밝혀주시기 바랍니다.
| 1. | ⇡ | https://www.gartner.com/smarterwithgartner/gartner-top-10-strategic-technology-trends-for-2020/ |
| 2. | ⇡ | https://github.com/cleverhans-lab/cleverhans |
| 3. | ⇡ | https://github.com/Trusted-AI/adversarial-robustness-toolbox |
| 4. | ⇡ | https://atlas.mitre.org/ |
![[Vol.12] 개인정보 정책에서 증거기반(evidence-based)의 규제의 필요성](https://hiic.re.kr/wp-content/uploads/bfi_thumb/dummy-transparent-qzswzze6g081azganrruhb07lbpw5dlcswvfm3xzys.png)