


[Vol.8] 미국의 국가 인공지능 연구 자원 태스크 포스 (NAIRR: The National Artificial Intelligence Research Resource Task Force) 구성의 의미와 향후 추진 계획
미국의 국가 인공지능 연구 자원 태스크 포스 (NAIRR: The National Artificial Intelligence Research Resource Task Force) 구성의 의미와 향후 추진 계획
한상기 ([email protected])
테크프론티어 대표
미국 정부가 지난 6월 12명으로 구성한 국가 인공지능 연구 자원 태스크 포스를 구성해 정부 데이터를 좀 더 인공지능에 전략적으로 활용할 방안을 논의한다고 발표했다.(1)이 TF는 2020년 국가 인공지능 이니셔티브 법(2)에 의해 추진하는 활동이며 백악관 과학기술정책실(OSTP)과 국립과학재단(NSF)의 협력에 의해 추진된다.
이런 움직임은 기본적으로 미국이 기술 발전의 선봉에 서야 한다는 미 정부의 강한 의지를 나타내는 최근 일련과 과정 중 하나이다. 미 상원은 6월에 기술 연구 개발에 2,500억 달러를 투자하는 법안을 양당 합의로 통과했으며 하원도 비슷한 법안을 만들고자 하고 있다.(3) 이는 특히 인공지능 분야에서 중국의 도전에 적극적으로 대응하고자 하는 의도도 담고 있다. KISA 리포트 지난 4월에서는 인공지능 국가 안보 위원회(NSCAI) 보고서를 소개한 적이 있는데, 이 역시 이런 흐름 중 하나의 결과라고 본다.
정부 보유 데이터를 활용하자는 요구는 2018년 트럼프 정부에서 개최한 인공지능에 관한 컨퍼런스에서 이미 제기되었고, 이번 TF는 바이든 정부에서 실제로 추진하고 있는 것이다. 이 TF의 활동 보고서는 2022년 5월과 11월에 나올 예정인데, 이를 통해 미 의회에 미 정부가 외부에 제공할 수 있는 공동 연구 인프라 구축을 위한 로드맵을 제시하는 것도 또 하나의 목적이다.
공동 의장인 린 파커에 따르면 인공지능에서 진짜 대단한 아이디어를 추구하려면 강력한 컴퓨팅 인프라와 함께 데이터에 접근할 수 있어야 하며 그렇지 못할 경우 이는 혁신을 방해할 것이라는 의견이다.
미국 연방 정부가 인공지능 데이터로 전환해야 하는 데이터는 예를 들면 교통부의 경우 차량 센서로부터 사람들이 운전하는 행태에 대한 데이터가 있을 수 있다. 그러나 이런 데이터가 개인에 관련한 매우 예민한 데이터일 수 있기 때문에 이를 광범위한 연구 커뮤니티에 제공하는 데에는 어려운 도전이 많을 것이다. 그러나 이런 데이터를 갖춘다면 운전을 좀 더 안전하게 할 수 있는 혁신이 이루어질 수도 있다.
익명 센서스, 의료 데이터 등을 민간 기업이나 학술 연구소에게 연구용으로 제공할 수 있다. 이 TF는 미국인의 프라이버시나 기타 윤리적 이슈를 지키면서 이런 데이터를 활용할 수 있게 만드는 방식에 대해서도 평가할 것이다. 또한 데이터는 비정부 기구의 것도 고려할 것이다. 위원 중에 인공지능 클라우드 관련자들은 이를 클라우드에서 어떻게 지원 활용할 것인가를 제시할 것이다.
2021년 국방 수권법을 통해서 의회는 이 TF가 공동의 인공지능 연구 인프라를 위한 청사진을 개발하라고 명령했다.(4)단지 데이터뿐만 아니라 인공지능 분야의 연구자와 학생이 교육 도구, 데이터, 계산을 위한 자원에 접근할 수 있도록 하고자 한다.
주요 위원 구성
미 의회가 지명한대로 OSTP의 국장과 NSF 국장 또는 그들이 지명하는 사람이 TF의 공동 의장이 되며, 12명의 전문가를 정부, 고등 교육 기관의 연구소, 민간 기관에서 각각 4명씩을 선발하기로 되어 있다. 이번에 선정된 위원은 다음과 같다.
- 린 파커 (공동 의장) – 국가 인공지능 이니셔티브 국장이며 미국 CTO 대행, OSTP의 인공지능 부국장
- 어윈 지안찬다니 (공동 의장) – NSF의 수석 고문 (번역, 혁신, 파트너십 담당)
- 다니엘라 브라가 – 디파인드크라우드(DefinedCrowd) 창업자 및 CEO
- 마크 딘 – 테네시 대학 명예 교수, 뉴로모픽 컴퓨팅 전문가
- 오렌 에찌오니 – 알렌 인공지능 연구소 CEO
- 줄리아 레인 – 뉴욕대학 교수, 콜러리지 이니셔티브 CEO
- 페이-페이 리 – 스탠포드 대학 교수, 스탠포드 인간 중심 인공지능 연구소 공동 소장
- 앤드류 무어 – 구글 클라우드 인공지능과 산업 솔루션 부사장 겸 총괄
- 마이클 노만 – UC 샌디에이고 물리학 교수, 샌디에이고 수퍼 컴퓨터 센터장
- 댄 스태지오니 – 오스틴의 텍사스 대학 연구소 부사장 겸 텍사스 첨단 컴퓨팅 센터 소장
- 프레데릭 스트라이츠 – 미 에너지 부 인공지능과 기술국 수석 과학 고문
- 엘햄 타바시 – 국립 표준 기술 연구소(NIST) 정보 기술 랩(ITL) 수석 스태프, NIST의 신뢰할 수 있는 인공지능 프로그램 리드
위원 면면을 보면 인공지능 분야의 최고 권위자만 아니라 차세대 컴퓨팅 기술, 정부 기관 내 인공지능 정책 전문가로 이루어졌으며, 여성의 비중도 12명 중 5명으로 성별이 한쪽으로 치우치지 않게 신경을 쓴 것으로 보인다.
TF 구성원 외에 외부 자문 기관도 있는데 여기에는 다음과 같은 기관이 있다.
- 국립 과학 재단(NSF)
- OSTP
- 전미 과학 공학 의학 한림원
- 국립 표준 기술 연구소(NIST)
- 국가 정보국 국장
- 에너지부
- 국방부
- 연방 조달청(GSA)
- 법무부
- 국토안보부
- 보건복지부
- 민간 산업
- 고등 교육 기관의 연구소들
- 시민과 장애인 권리 관련 기관
- TF가 적절하다고 인정하는 사람들
향후 진행 일정
태스크포스는 2021년에 네 번의 회의를 할 예정이며 1차 회의는 7월 28일에 열렸다. 이후 8월 30일, 10월 25일, 12월 13일에 회의를 가질 예정이고, 그 내용은 모두 공개한다.
7월 28일에 가진 1차 회의에서는 TF의 의무와 목적, 연방 자문 위원회 규칙에 대한 기본 이해, 인공지능 R&D를 지원하는 상업용 클라우드 자원을 연방 차원에서 어떻게 사용하고 있는가에 대한 현황, TF 업무 계획에 대한 실행안과 동의, 후속 미팅에 대한 브리핑과 자문 확인 등이 이루어졌다.
1차 미팅에서는 NAIRR의 바람직한 특성과 주요 도전 이슈에 대해 그리고 TF를 위한 워크플랜 제안에 대해 토의가 있었고, 인공지능 R&D를 위한 연방 클라우드 파일럿 과제에서 얻은 교훈과 스트라이즈(STRIDES) 파일럿 과제 케이스에 대한 발표도 있었다. 두 번째 발표는 국립 의료원의 케이스였다.
1차 회의 이전에는 OSTP와 NSF가 일반 시민을 상대로 RFI를 7월 23일에 발행했다 (86 FR 39081). 의견은 10월 1일까지 받기도 했으며 다음과 같은 질의를 제시했다.
- TF가 로드맵에서 고려할 다른 옵션은 무엇이 있으며 그 이유는?
- NAIRR에서 우선순위로 해야 하는 역량이나 서비스는 무엇인가?
- NAIRR이나 하위 구성 요소에서 인공지능의 윤리적이고 책임지는 연구 개발 원칙을 어떻게 강화할 것인가? 현재 우려하는 인종과 젠더 공평, 공정성, 편향, 시민권, 투명성, 책무성과 같은 이슈들
- 정부, 학계, 민간 섹터 행위, 자원과 서비스에서 이미 존재하는 빌딩 블록은 무엇인가?
- 공공-민간 파트너십이 NAIRR에서 할 수 있는 역할은 무엇인가? 어떤 사례가 모델이 되는가?
- 인공지능 R&D에 대한 민주적 접근에 대한 NAIRR의 능력에서 한계는 무엇인가? 이런 한계를 어떻게 극복할 것인가?
태스크포스가 제시한 향후 일정은 아래와 같아. 2022년 2월까지 평가 기간을 가지며, 5월에 중간 보고서를 내년 11월에 최종 보고서를 제출할 예정이다.
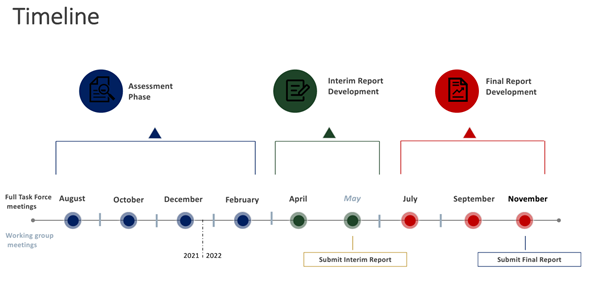
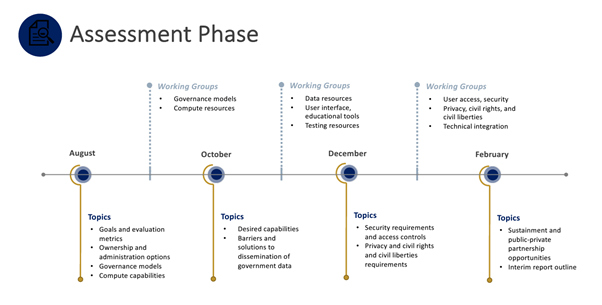
2022년 2월까지의 평가 기간 중에는 주제 선정과 워킹 그룹을 만들 것인데, 워킹 그룹을 살펴보면 거버넌스, 계산 자원, 데이터 자원, 사용자 인터페이스와 교육 도구, 검사 자원, 사용자 접근과 보안, 프라이버시/시민권/시민 자유, 기술 통합 워킹 그룹을 구성할 계획이다.
TF 멤버는 8월 3일까지 선호하는 워킹 그룹을 제안하고 모델이나 자문에 대한 아이디어를 제출해야 한다. 공동 의장은 회의록을 보내고 미팅에 앞서 필요한 로지스틱스와 어젠다를 준비하기로 했다.
나가며
미국은 이제 인공지능 분야에서 최강국이지만 앞으로도 경쟁력을 유지하고 뒤따라오는 중국 같은 나라와 크게 격차를 벌리고자 한다. 이를 위해 수천억 달러를 투자하는 것 외에도 각 지역별로 차별적인 인공지능 연구소를 설립하고 모든 산업 분야에서 인공지능 적용을 깊이 있게 연구하고자 한다.
이번에 시작하는 인공지능 연구 자원 TF는 이제 연방 정부 기관들이 갖고 있는 막대한 자료를 인공지능 연구를 위한 데이터로 제공하겠다는 것이고 이를 위한 컴퓨팅 자원이나 교육 도구 등을 만들어 학계와 민간이 과거에 접할 수 없었던 영역에서 인공지능 응용을 적극 추진하겠다는 의미이다.
우리나라도 인공지능 데이터셋을 만들어 공개하는 과업이 2020년부터 국가 차원의 디지털 뉴딜 정책의 일환으로 이루어지고 있지만, 정부나 공공 기관이 갖고 있는 고품질의 대규모 데이터를 기반으로 연구 개발을 위한 데이터셋을 만드는 것은 아직 많이 부족한 상황이다. 현재 민간 기업에서 활용할 수 있는 응용 중심의 데이터셋 구축을 확장하거나 내년부터는 좀 더 공공성이 높거나 학술 가치가 있는 데이터셋 구축에 대해서도 관심을 가질 필요가 있다.
본 원고는 KISA Report에서 발췌된 것으로 한국인터넷진흥원 홈페이지(https://www.kisa.or.kr/public/library/IS_List.jsp)에서도 확인하실 수 있습니다.
KISA Report에 실린 내용은 필자의 개인적 견해이므로, 한국인터넷진흥원의 공식 견해와 다를 수 있습니다.
KISA Report의 내용은 무단 전재를 금하며, 가공 또는 인용할 경우 반드시 [한국인터넷진흥원,KISA Report]라고 출처를 밝혀주시기 바랍니다.
| 1. | ⇡ | The Wall Street Journal, “U.S. Launches Task Force to Study Opening Government Data for AI Research”, Jun 10, 2021 |
| 2. | ⇡ | Congress.gov, “H.R.6216 – National Artificial Intelligence Initiative Act of 2020”, May 12, 2020 |
| 3. | ⇡ | The Wall Street Journal, “Senate Approves $250 Billion Bill to Boost Tech Research”, Jun 8, 2021 |
| 4. | ⇡ | ExecutiveGov, “NAIRR Task Force Extends Deadline for Roadmap Public Comments; Erwin Gianchandani Quoted”, Aug 19, 2021 |
![[Vol.12] 개인정보 정책에서 증거기반(evidence-based)의 규제의 필요성](https://hiic.re.kr/wp-content/uploads/bfi_thumb/dummy-transparent-qzswzze6g081azganrruhb07lbpw5dlcswvfm3xzys.png)